Главные риски AI (Artificial Intelligence - искусственный интеллект) - рекомендательных систем
Современный цифровой мир перенасыщен информацией. В условиях бесконечного выбора рекомендательные системы (RecSys) жизненная необходимость для бизнеса, так как они подстраиваются под конкретного пользователя и повышают коэффициент удержание клиента в продукте.
Однако персонализация — это палка о двух концах. Вместо полезной информации, пользователь может столкнуться с потоком нелепых и оскорбительных предложений всего из-за одной ошибки в сценарии.
Тестирование персонализации — это сложный процесс на стыке классического обеспечения качества, анализа данных (Data Science) и продуктовой аналитики. В этой статье разберем, как выстроить стратегию проверки рекомендательных алгоритмов.
Почему стандартных тестов недостаточно?
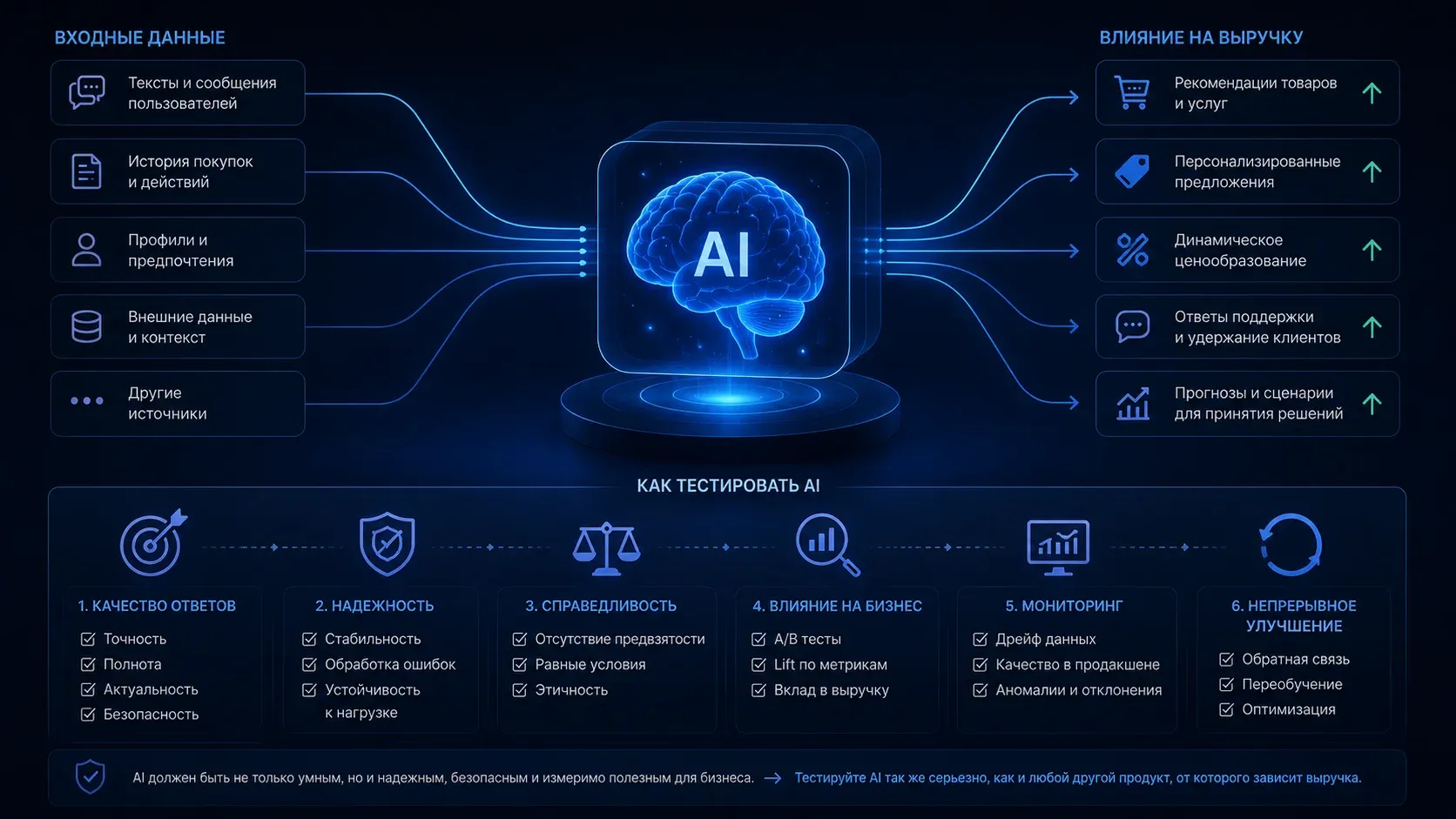
Традиционное функциональное тестирование опирается на предсказуемость. За абстрактным действием А должно последовать действие Б и, если этого не произошло или произошло неверно, можно фиксировать ошибку.
В персонализации результат зависит от огромного количества переменных. Это история кликов, геолокация, время суток, поведения похожих пользователей из той же группы (коллаборативная фильтрация), метаданные контента и многие другие переменные.
Таким образом ключевые сложности при проверке RecSys это:
Постоянное изменение данных;
Новые пользователи без истории взаимодействия с продуктом;
Субъективность пользовательского восприятия.
Доверьте тестирование ваших продуктов профессиональной команде экспертов
Как построить процесс тестирования рекомендательной системы
Проверку такой сложной системы нужно разделить на несколько логических этапов.
Тестирование качества данных (Data Quality)
Рекомендательная система хороша ровно настолько, насколько чисты данные, на которых она обучается.
Проверка ETL-процессов (Extract, Transform, Load): корректно ли данные собираются из логов и передаются в хранилище?
Полнота профиля: проверяем, как система обрабатывает пустые поля или противоречивую информацию (например, когда пользователь сменил регион или его интересы изменились).
Проверка алгоритмов и логики (Backend Testing)
На этом этапе важно использовать методы Offline Evaluation (офлайн-оценки). Используются метрики, которые показывают точность предсказаний на основе собранных ранее данных:
Precision@kи Recall@k: какая доля из топа рекомендаций оказалась интересной пользователю?
MRR (Mean Reciprocal Rank): насколько высоко в списке находится первая релевантная по отношению к пользовательским интересам позиция?
nDCG (Normalized Discounted Cumulative Gain): каков порядок ранжирования? Очевидно, что наиболее релевантные рекомендации должны быть в самом начале.
Тестирование сценариев и бизнес-правил
Здесь QA-инженеру необходимо проверить ограничения, которые накладывает бизнес-логика проверяемого продукта.
Фильтрация контента: исключение дублирования товаров или услуг, уже проданных товаров или взрослого контента для аккаунтов несовершеннолетних владельцев.
Разнообразие (Diversity): система не должна рекомендовать подряд одно и то же, даже если с точки зрения системы это разные товары (например, белые футболки разных производителей).
Новизна (Novelty): аккуратное добавление новых категорий, чтобы пользователь не оказался «заперт» внутри одной товарной группы.
Наши специалисты проведут комплексную оценку вашего приложения и предоставят подробный отчет с рекомендациями
Для качественного тестирования персонализации необходимо использовать различные инструменты и методики тестирования. Только таким образом возможно учесть все нюансы системы.
А/B-тестирование: единственный способ узнать, как изменения влияют на бизнес-метрики (CTR, конверсия, LTV). Для управления экспериментами часто используют такие сервисы, как Google Optimize, Optimizely или внутренние самописные платформы.
Shadow Testing (Теневое тестирование): запуск новой модели одновременно с основной. Новая модель генерирует ответы, они логируются, но не показываются пользователю. Это позволяет сравнить точность рекомендаций в этих двух моделях без риска для продукта.
Proxy-серверы и подмена геолокации: использование Charles Proxy или Fiddler для имитации запросов из разных стран и с разными User-Agent.
Скрипты генерации профилей: автоматизация создания синтетических пользователей с разными паттернами поведения (например, «шопоголик», «экономный», «случайный посетитель» и т.д.).
С усложнением рекомендательных систем на базе больших языковых моделей (LLM) и нейросетей, ручное тестирование становится неэффективным. Подход смещается в сторону концепции Model Monitoring.
В рамках этой методологии отслеживается дрейф модели (Model Drift). Со временем интересы пользователей меняются, и вчерашняя эффективная рекомендационная модель довольно быстро перестает ей быть.
Автоматизированные системы мониторинга (например, WhyLabs или Arize AI) помогают вовремя заметить падение метрик, показывающих качество рекомендаций и отправить модель на дообучение.
Таким образом, главная цель тестирования систем персонализации — это гарантировать, что система останется человекоцентричной, то есть будет служить интересам пользователей и бизнеса.
Лояльность клиентов строится годами, а разрушается короткой чередой неуместных рекомендаций, будь то список товаров на маркетплейсе или подборка музыкальных композиций в предлагаемом плейлисте.